Inhaltsverzeichnis
Graphen Algorithmen in der Oracle Datenbank umsetzen und mit PGQL und / oder SQL abfragen
Aufgabe:
In Python ist es relativ einfach, mit Hilfe von Libraries, eine Aufgaben über den Graphen Ansatz umzusetzen.
- Wie kann das ganze aber nun auch in der Oracle Datenbank intern für den produktiven Einsatz genützt werden?
- Wie kann in der Datenbank mit PGQL ( Opensource ⇒ https://pgql-lang.org/) nach Pattern in Graphen gesucht werden?
- Wie aber das ganze in einen klassischen Oracle ETL Job auf PL/SQL Basis integrieren?
Die Architektur der Graphen Option der Datenbank
Mit Oracle stehen dem Entwickler zwei Optionen zur Implementierung von Graphen Algorithmen zur Verfügung.
Einmal über den PGX Server mit allen nur denkbaren Funktionen und Feature und über die Datenbank mit einigen wichtigen Basis Algorithmen.
Siehe dazu ⇒ https://docs.oracle.com/cd/E56133_01/2.7.0/reference/overview/index.html
D.h. für das Speicher und rudimentäre Abfragen auf Graphen ist die Datenbank alleine ausreichend, hier kann komplett auf PL/SQL gesetzt werden.
Sollen aber komplexe Algorithmen auf dem Graphen angewandt werden, benötigen wir neben der Datenbank noch den PGX Server.
Der wird zwar mit der DB ausgeliefert und muss „nur“ gestartet werden. Das wiederum kann in extern gehosteten Umgebungen und komplexen/unklaren IT Strukturen im Unternehmen aber zu einer echten Herausforderung werden.
Lizenz
Für diese Option ist seit Dezember 2019 keine eigene Lizenz mehr notwendig.
Siehe dazu:
Einführung
- Vertex oder node oder point ⇒ Knotenpunkt
- edge oder line ⇒ Kante
- Connected Components ⇒ Zusammenhangskomponente ⇒ ein maximal zusammenhängenden Teilgraph

Unser erstes Model ist bewusst so einfach wie möglich gehalten, damit wir die Daten besser nachvollziehen können.
In der Relationalen Welt legen wir uns also zwei Tabellen an:
CREATE TABLE vertex ( name varchar2(1), valueA varchar2(256)); CREATE UNIQUE INDEX idx_vertex_pk ON vertex(name); CREATE TABLE edge ( edge_id NUMBER, Name_from varchar2(1), Name_to varchar2(1) ,VALUE varchar2(256)); CREATE UNIQUE INDEX idx_edge_pk ON edge(edge_id); CREATE SEQUENCE seq_edge; INSERT INTO vertex VALUES ( 'A','Andreas'); INSERT INTO vertex VALUES ( 'B','Berta'); INSERT INTO vertex VALUES ( 'C','Cäsar'); INSERT INTO vertex VALUES ( 'D','Dieter'); INSERT INTO vertex VALUES ( 'E','Emilie'); INSERT INTO vertex VALUES ( 'F','Franzi'); INSERT INTO vertex VALUES ( 'G','Gunther'); INSERT INTO edge VALUES ( seq_edge.nextval,'A','B','verlobt'); INSERT INTO edge VALUES ( seq_edge.nextval,'A','C','bekannt'); INSERT INTO edge VALUES ( seq_edge.nextval,'C','D','befreundet'); INSERT INTO edge VALUES ( seq_edge.nextval,'C','E','verlobt'); INSERT INTO edge VALUES ( seq_edge.nextval,'C','F','befreundet'); INSERT INTO edge VALUES ( seq_edge.nextval,'F','G','bekannt'); INSERT INTO edge VALUES ( seq_edge.nextval,'C','G','bekannt'); commit;
Nach dem Test wieder löschen .-)
DROP TABLE vertex ; DROP TABLE edge ; DROP SEQUENCE seq_edge;
Voraussetzung in der Datenbank
Gerade der Punkt mit „EXTENDED VARCHAR2“ könnte sich auf einer EXDATA mit einen hoch kritischen DWH als schwierig bis organisatorisch unmöglich herausstellen.
Prüfen
Package OPG_APIS in der DB im Zugriff für den verwendeten User!
SELECT owner,object_name FROM all_objects WHERE object_name='OPG_APIS'; OWNER OBJECTNAME ---- ----- PUBLIC OPG_APIS MDSYS OPG_APIS MDSYS OPG_APIS
Falls das hier fehlt ⇒ Steps for Manual Installation / Verification of Spatial 10g / 11g /12c (Doc ID 270588.1) bzw. Information Center: Oracle Spatial Installation and Upgrade (Doc ID 1551262.2)
EXTENDED VARCHAR2 in der DB aktivieren
Auch muss der EXTENDED VARCHAR2 in der DB aktiviert sein!
SHUTDOWN IMMEDIATE STARTUP UPGRADE ALTER SYSTEM SET max_string_size=extended; @?/rdbms/admin/utl32k @?/rdbms/admin/utlrp.sql SHUTDOWN IMMEDIATE STARTUP
⇒ Ansonsten wird der Fehler siehe ⇒ „OPG_APIS.CREATE_PG fails with ORA-00910: specified length too long for its datatype (Doc ID 2463898.1)“ geworfen!
Plugin für SQLcl aktivieren
Um die Graphen Abfrage Sprache PQGL verwenden zu können, benötigen wir eine entsprechende Schell, die die Syntax auch versteht.
Zuvor also SQLcl installieren; siehe dazu ⇒ SQLcl - Quo vadis SQL*Plus? - Das neue SQL*Plus in der Praxis - Der neue SQL Kommando Interpreter für die Oracle Datenbank
Vorbereitung
Beschrieben ist hier unter MS Windows der Ablauf mit der Powershell; SQLcl wird in „H:\tools\sqlcl“ installiert.
- Download SQlcl Addon - „Oracle Graph Server and Client 20.4.0.0.0“ oder höher von ⇒ https://edelivery.oracle.com/osdc/faces/SoftwareDelivery ( Produkt „Oracle Graph Server and Client“ in die Suchmaske eingeben und suchen!). Auch die „Digest Details“ anzeigen lassen um später zu prüfen ob die Dateien in Ordnung sind!
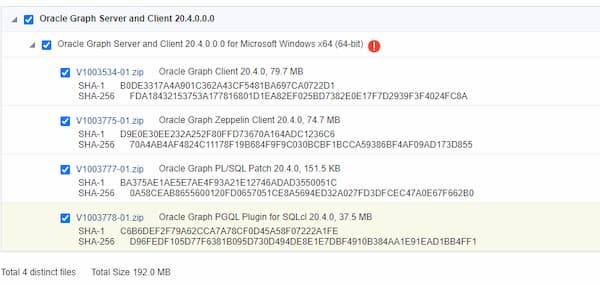
- Plugin in SQlcl aktivieren
- Datei „V1003778-01.zip -Oracle Graph PGQL Plugin for SQLcl 20.4.0, 37.5 MB“ Integrität prüfen
-- D96FEDF105D77F6381B095D730D494DE8E1E7DBF4910B384AA1E91EAD1BB4FF1 Get-FileHash V1003778-01.zip | Format-List Algorithm : SHA256 Hash : D96FEDF105D77F6381B095D730D494DE8E1E7DBF4910B384AA1E91EAD1BB4FF1 Path : H:\tools\Graph\V1003778-01.zip
Passt!
- Datei auspacken
Expand-Archive -Path H:\tools\Graph\V1003778-01.zip -DestinationPath H:\tools\Graph\SQLclPlugin20_4 Expand-Archive -Path H:\tools\Graph\SQLclPlugin20_4\oracle-graph-sqlcl-plugin-20.4.0.zip -DestinationPath H:\tools\Graph\SQLclPlugin20_4
- Jars in das SQLcl Library Verzeichnis kopieren
cd H:\tools\Graph\SQLclPlugin20_4 copy *.jar H:\tools\sqlcl\lib\ext\

An der Datenbank anmelden und Plugin testen
Nun kann SQLcl gestartet werden und mit dem Setting „pgql auto on“ wird der PGQL Modus aktiviert.
H:\tools\sqlcl\bin\SQL.exe GPI@GPIDB pgql auto ON PGQL Auto enabled FOR graph=[NULL], EXECUTE=[TRUE], translate=[FALSE]
Probleme beim ersten Test
PLS-00201: ID 'OPG_APIS.CREATE_PG'
Error: java.sql.SQLException: ORA-06550: Zeile 1, Spalte 7: PLS-00201: ID 'OPG_APIS.CREATE_PG' muss deklariert werden ORA-06550: Zeile 1, Spalte 7: PL/SQL: Statement ignored
Spatial Option nicht installiert!
ORA-00910: specified length too long for its datatype
siehe ⇒ OPG_APIS.CREATE_PG fails with ORA-00910: specified length too long for its datatype (Doc ID 2463898.1)
Ursache: Property Graph is using the EXTENDED VARCHAR2 types that accepts strings up to 32767 bytes.
Lösung:
Enable EXTENDED VARCHAR2 support in the database
Enable EXTENDED VARCHAR2 support IN the DATABASE SHUTDOWN IMMEDIATE STARTUP UPGRADE ALTER SYSTEM SET max_string_size=extended; @?/rdbms/admin/utl32k @?/rdbms/admin/utlrp.sql SHUTDOWN IMMEDIATE STARTUP
Basis PGQL Abfragen - Ein erstes Beispiel
Über SQLcl dann direkt mit der Property Graph Query Language (PGQL) gearbeitet werden ⇒ siehe auch ⇒ https://docs.oracle.com/en/database/oracle/oracle-database/20/spgdg/property-graph-query-language-pgql.html und https://pgql-lang.org/spec/1.3/
Dazu wird SQLcl gestartet, an der DB angemeldet und mit „pgql auto ON“ der PGQL aktiviert.
sql>pgql auto ON PGQL Auto enabled FOR graph=[NULL], EXECUTE=[TRUE], translate=[FALSE] PGQL>
Modell erstellen
Nun kann ein „property Graph“ auf Basis unseres Relationalen Tabellen Modells angelegt oder mit diesem gearbeitet werden.
Falls dieser schon existiert, diesen als Default setzen:
PGQL> pgql auto ON graph simple_map
Neu anlegen:
PGQL> CREATE property graph simple_map vertex TABLES ( vertex KEY (name ) Label Knoten Properties (name,valueA ) ) edge TABLES ( edge KEY(edge_id ) SOURCE KEY (Name_from ) REFERENCES vertex Destination KEY (Name_to ) REFERENCES vertex Label Beziehung Properties (VALUE) );
.
Mit dem Anlegen des Graphen werden die Daten umkopiert und in einem eigenen DB Modell gespeichert!
Die Daten des Graphen werden dann relational in einem eigenen Modell ( PG / FLAT-FILE Format ) aus 5 Tabellen abgelegt:
- xxxGE$ ⇒ Edge / Kanten
- xxxxVT$ ⇒ Vertex/ Knoten
- xxxxGT$ ⇒ Graph Skeleton
- xxxxIT$ ⇒ Text Index Metadata
- xxxxSS$ ⇒ Graph Snapshots
Modell mit SQLcl abfagen
Nun kann der Graph abgefragt werden (in einigen Beispielen im Netz kann die From Klausel entfallen, das finde ich aber sehr SQL ungewöhnlich und bzgl. Lesbarkeit rate ich davon ab)
Der Match Operator erzeugt für das Resultset auf dem man arbeiten möchte, die verwendeten Variablen können dann referenziert werden um die Daten auszulesen.
Der PGQL Pfads besteht aus „()“ Nodes und „[]“ Edges die mit „-“ „←“ etc verknüpft werden., wie „(KNOTEN) - [EDGE] → (ZWEITER_KNOTEN)“.
Über Labels kann auf den Typ eines Knoten oder Kante referenziert werden (zuvor im Model definiert!) wie „(KNOTEN) - [EDGE:Beziehung] → (ZWEITER_KNOTEN)
-- Anzahl knoten PGQL> SELECT COUNT(alle_knoten) FROM MATCH (alle_knoten); COUNT(alle_knoten) _____________________ 7 -- Anzahl der Kanten PGQL> SELECT COUNT(edge) FROM MATCH ( (FROM) -[edge]-> (TO) ); COUNT(edge) ______________ 7 -- Kanten mit Eigenschaft auflisten in Richtung from => to PGQL> SELECT a.valueA AS FROM ,e.value,b.valueA AS TO FROM MATCH ( (a)-[e]->(b) ); FROM VALUE TO __________ _____________ __________ Franzi bekannt Gunther Andreas bekannt Cäsar Andreas verlobt Berta Cäsar befreundet Dieter Cäsar verlobt Emilie Cäsar befreundet Franzi -- Kanten mit Eigenschaft auflisten in der anderen Richtung PGQL> SELECT a.valueA AS FROM ,e.value,b.valueA AS TO FROM MATCH ( (a)<-[e]-(b) ); FROM VALUE TO __________ _____________ __________ Gunther bekannt Franzi Cäsar bekannt Andreas Berta verlobt Andreas Dieter befreundet Cäsar Emilie verlobt Cäsar Franzi befreundet Cäsar
Nun gut.. das hätten wir wohl mit SQL auch hinbekommen.
Jetzt wollen wir wissen wie weit A von G entfernt ist:
-- erster Test mit zwei festen Knoten PGQL> SELECT a.valueA AS FROM, b.valueA AS TO FROM MATCH ( (a) -> (z) -> (y) -> (b) ); FROM TO __________ __________ Andreas Gunther -- Bzw mit einem regulären Ausdruck: PGQL> SELECT a.name AS FROM , b.name AS tooo FROM MATCH (a)-/:beziehung{3,}/->(b) WHERE b.name='G'; FROM TOOO _______ _______ A G
Nach dem Test wieder löschen:
DROP property graph simple_map
Die Frage ist nun ob es sich lohn weiter mit der Sprache zu beschäftigen.
Für den Einsatz in PL/SQL innerhalb der Datenbank wird ja dann wiederum ein Mapping auf eine Java Klasse in der die Abfrage dann definiert wird, benötigt.
Daher versuche ich im nächsten Schritt wie weit sich die Aufgaben mit SQL und PL/SQL Lössen lassen ohne eben weitere Software einsetzen zu müssen.
Modell mit PLSQL abfragen
Das Modell kann auch per PL/SQL erstellt/gefüllt und abgefragt werden.
siehe ⇒ https://docs.oracle.com/en/database/oracle/oracle-database/12.2/spgdg/OPG_APIS-reference.html
Hier wird dann direkt auf den Modell Metadaten Tabellen per „normalen“ SQL gearbeitet.
Das Modell als Tabellen Strukur anlegen
Modell per PL/SQL anlegen:
BEGIN OPG_APIS.CREATE_PG( graph_name =>'GPI_GRAPH'); END; /
Bzw:
OPG_APIS.CREATE_PG( ,graph_name => 'GPI_GRAPH' -- Name of the property graph. ,dop => 8 -- Degree of parallelism for the operation. ,num_hash_ptns => 16 -- Number of hash partitions used to partition the vertices -- and edges tables. -- It is recommended to use a power of 2 (2, 4, 8, 16). ,tbs => 'USERS' -- Name of the tablespace to hold all the graph data and index data. ,options => 'IMC_MC_B=T' -- Options that can be used to customize the creation of indexes on schema tables -- 'SKIP_INDEX=T' skips the default index creation. -- 'SKIP_ERROR=T' ignores errors encountered during table/index creation. -- 'INMEMORY=T' creqtes the schema tables with an INMEMORYclause. -- 'IMC_MC_B=T' creates the schema tables with an INMEMORY BASIC clause. ); BEGIN OPG_APIS.CREATE_PG( graph_name => 'GPI_GRAPH' ,dop => 8 ,num_hash_ptns => 16 ,tbs => 'USERS' -- ,options => 'IMC_MC_B=T' -- only if in memory enabled! ); END; /
Zu „IMC_MC_B=T“, das Database In-Memory Base Level Feature ist in der 19c ohne weitere Lizenz ab 19.8 RU verfügbar. Der init.ora Parameer INMEMORY_FORCE muss auf den Wert BASE_LEVEL und der INMEMORY_SIZE kann bis auf den Wert von 16GB gesetzt werden; siehe dazu auch ⇒ https://docs.oracle.com/en/database/oracle/oracle-database/19/inmem/intro-to-in-memory-column-store.html .
Die Daten des Graphen werden dann relational in einem eigenen Modell ( PG / FLAT-FILE format ) aus 5 Tabellen abgelegt:
- GPI_GRAPHGE$ ⇒ Edge / Kanten
- GPI_GRAPHVT$ ⇒ Vertex/Knoten
- GPI_GRAPHGT$ ⇒ Graph Skeleton
- GPI_GRAPHIT$ ⇒ Text Index metadata
- GPI_GRAPHSS$ ⇒ Graph Snapshots
Die beiden wichtigsten Tabellen:

xxxVT$ im Detail
| Spalte | Daten Typ | Beschreibung |
|---|---|---|
| VID | NUMBER | Vertex IT |
| K | NVARCHAR2(3100) | Property Key |
| T | NUMBER(38) | Property value type see https://docs.oracle.com/cd/E56133_01/latest/reference/loader/file-system/plain-text-formats.html |
| V | NVARCHAR2(15000) | Property Value as Text |
| VN | NUMBER | Property Value as Numeric |
| VT | TIMESTAMP(6) WITH TIME ZONE | Property Value as Daten & Time |
| SL | NUMBER | Security Label |
| VTS | DATE | Validity start |
| VTE | DATE | Validity end |
| FE | NVARCHAR2(4000) |
xxxGE$ im Detail
| Spalte | Daten Typ | Beschreibung |
|---|---|---|
| EID | NUMBER | Edge Id |
| SVID | NUMBER | Source vertex ID |
| DVID | NUMBER | Destination vertex Id |
| EL | NVARCHAR2(3100) | Edge Label |
| K | NVARCHAR2(3100) | Property Key |
| T | NUMBER(38) | Property value type see https://docs.oracle.com/cd/E56133_01/latest/reference/loader/file-system/plain-text-formats.html |
| V | NVARCHAR2(15000) | Property Value as Text |
| VN | NUMBER | Property Value as Numeric |
| VT | TIMESTAMP(6) WITH TIME ZONE | Property Value as Daten & Time |
| SL | NUMBER | Security Label |
| VTS | DATE | Validity start |
| VTE | DATE | Validity end |
| FE | NVARCHAR2(4000) |
Die Datentypen Typen:
| STRING | 1 |
| INTEGER | 2 |
| FLOAT | 3 |
| DOUBLE | 4 |
| DATE LOCAL_DATE TIME TIMESTAMP TIME_WITH_TIMEZONE TIMESTAMP_WITH_TIMEZONE | 5 |
| BOOLEAN | 6 |
| LONG | 7 |
| POINT2D | 20 |
siehe bzgl. direkt Abfrage der Modell Tabellen ⇒ https://docs.oracle.com/en/database/oracle/oracle-database/18/spgdg/sql-based-property-graph-query-analytics.html#GUID-DA3E5ADB-5851-4686-8418-EFF473794846
Modell kann nun per SQL mit Insert Befehlen gefüllt werden.
Wie:
--knoten INSERT INTO GPI_GRAPHVT$ (VID, K, T, V) VALUES ( 1000, 'Name' , 1 , 'Hugo'); --Relationen INSERT INTO GPI_GRAPHGE$ (EID, SVID, DVID, EL, K, T, V, VN ) VALUES( GPI_GRAPHL_EDGE_SEQ.nextval, 1000, 2000, 'Beziehung','xxxxx', 1, '1000', 1000 );
Nachdem das Model dann gefüllt ist kann mit PL/SQL eine Analyse auf den Daten durchgeführt werden.
Zuvor die Statistiken auf dem Graphen Tabellen akualiseren:
BEGIN OPG_APIS.ANALYZE_PG(graph_name => 'GPI_GRAPH' , estimate_percent=> 0.50 , method_opt=>'FOR ALL COLUMNS SIZE AUTO' , degree=>4 , cascade=>TRUE , no_invalidate=>FALSE , force=>TRUE , options=>NULL); END;
Ein connected components Cluster ermitteln:
SET serveroutput ON DECLARE wtClusters varchar2(200) := 'GPI_BEZ_CLUSTERS' ; wtUnDir varchar2(200):='GPI_GRAPH_WT_UN_DIR'; wtCluas varchar2(200):='GPI_GRAPH_WT_CLUAS' ; wtNewas varchar2(200):='GPI_GRAPH_WT_NEWAS' ; wtDelta varchar2(200):='GPI_GRAPH_WT_DELTA' ; v_edge_table varchar2(32):='GPI_GRAPHGE$'; BEGIN -- prepare the stage Table to hold the result opg_apis.find_clusters_prep( edge_tab_name => v_edge_table -- Name of the property graph edge table. ,wt_clusters => wtClusters -- working table holding the final vertex cluster mappings ,wt_undir => wtUnDir -- A working table holding an undirected version of the graph. ,wt_cluas => wtCluas -- A working table holding current cluster assignments. ,wt_newas => wtNewas -- A working table holding updated cluster assignments. ,wt_delta => wtDelta -- A working table holding changes ("delta") in cluster assignments. ,options => '' -- Additional settings for index creation. ); dbms_output.put_line('-- Info : working tables names ' || wtClusters || ' ' || wtUnDir || ' ' || wtCluas || ' ' || wtNewas || ' '|| wtDelta ); -- Finds connected components in a property graph. -- All connected components will be stored in the wt_clusters table. -- The original graph is treated as undirected. -- opg_apis.find_cc_mapping_based( edge_tab_name => v_edge_table -- Name of the property graph edge table. ,wt_clusters => wtClusters -- A working table holding the final vertex cluster mappings ,wt_undir => wtUnDir -- A working table holding an undirected version of the graph. ,wt_cluas => wtCluas -- A working table holding current cluster assignments. ,wt_newas => wtNewas -- A working table holding updated cluster assignments. ,wt_delta => wtDelta -- A working table holding changes ("delta") in cluster assignments. ,dop => 4 -- Degree of parallelism for the operation. The default is 4. ,rounds => 0 -- Maximum umber of iterations to perform in searching for connected components. The default value of 0 (zero) means that computation will continue until all connected components are found. ,tbs => 'USERS' -- Name of the tablespace to hold the data stored in working tables. ,options => 'PDML=T') -- Additional settings for the operation. 'PDML=T' enables parallel DML. ; END; /
Die Ergebnisse können dann in SQL Ausgewertet werden:
- Cluster SELECT COUNT(DISTINCT cluster_id) FROM GPI_BEZ_CLUSTERS; SELECT cluster_id, COUNT(*) FROM GPI_BEZ_CLUSTERS GROUP BY cluster_id; -- Vertex SELECT c.cluster_id , v.vid , v.k , v.v FROM GPI_GRAPHGE$ v INNER JOIN GPI_BEZ_CLUSTERS c ON ( c.vid = v.vid) ORDER BY c.cluster_id; -- EDGE SELECT c.cluster_id ,e.eid , e.svid , e.dvid , e.k , e.v FROM GPI_GRAPHGE$ e INNER JOIN GPI_BEZ_CLUSTERS c ON ( c.vid = e.svid) WHERE 1=1 ORDER BY c.cluster_id;
Wieder aufräumen:
DECLARE wtClusters varchar2(200) := 'GPI_BEZ_CLUSTERS' ; wtUnDir varchar2(200):='GPI_GRAPH_WT_UN_DIR'; wtCluas varchar2(200):='GPI_GRAPH_WT_CLUAS' ; wtNewas varchar2(200):='GPI_GRAPH_WT_NEWAS' ; wtDelta varchar2(200):='GPI_GRAPH_WT_DELTA' ; v_edge_table varchar2(32):='GPI_GRAPHGE$'; BEGIN -- cleanup all the working tables opg_apis.find_clusters_cleanup(v_edge_table, wtClusters, wtUnDir, wtCluas, wtNewas, wtDelta, ''); END; / BEGIN -- drop the graph OPG_APIS.DROP_PG( graph_name =>'GPI_GRAPH'); END; /
Daten visualisieren
- Software ⇒ https://cytoscape.org/download.html
- Plugin Oracle Spatial and Graph property graph support for Cytoscape ⇒ https://www.oracle.com/database/technologies/semantic-technologies-downloads.html für Cytoscape v3.2.1 or higher
- Cytoscape herunterladen und installieren inkl. Java 11
- Cytoscape starten (um das Home Verzeichnis für das Plugin zu erzeugen)
- Plugin in temp Verzeichnis auspacken und unter /Doc Anleitung für die Installation des Plugins lesen
- Jar <install_dir>/oracle_property_graph_cytoscape/jar/propertyGraphSupportRDBMS.jar nach <USER_HOME>/CytoscapeConfiguration/3/apps/installed kopieren
- Datei <install_dir>/oracle_property_graph_cytoscape/jar/propertyGraph.properties nach <USER_HOME>/CytoscapeConfiguration kopieren
Falls es nicht funktioniert:
- Java 11 JDK https://jdk.java.net/java-se-ri/11 in ein Verzeichnis „C:\java\jdk-11“ entpacken
- Datei „C:\Program Files\Cytoscape_v3.8.2\cytoscape.bat“ Zeile 180,181 direkt den Java Pfad anpassen
set JAVA_HOME=C:\java\jdk-11 set JAVA=%JAVA_HOME%\bin\java
- Über „C:\Program Files\Cytoscape_v3.8.2\cytoscape.bat“ starten
Leider geht es immer noch nicht …. Plugin wird ohne Fehlermeldung nicht geladen!
Versuch mit alter Version http://chianti.ucsd.edu/cytoscape-3.5.1/, diese ist im Screenshot der Doku zu erkennen.
Leider keine Verbesserung …
Siehe auch https://www.ateam-oracle.com/visualize-property-graph-with-cytoscape-spatial-and-graph-part-4
Quellen
Doku:
Einführung:
Beispiel:
Grundlagen:
Visualisierung
prüfen ob Java in der DB Funktioniert und welche Version zur Verfügung steht
siehe auch ⇒ Java in der Oracle Datenbank intern einsetzen
CREATE OR REPLACE java SOURCE named "Hello" AS public class Hello { public static String world() { return "Hallo, ich bin Java aus der DB"; } } / create or replace function helloWorld return varchar2 as language java name 'Hello.world() return java.lang.String'; / select HELLOWORLD from dual; Hallo, ich bin Java aus der DB CREATE OR REPLACE FUNCTION getJavaProperty(myprop IN VARCHAR2) RETURN VARCHAR2 IS LANGUAGE JAVA name 'java.lang.System.getProperty(java.lang.String) return java.lang.String'; / SELECT getJavaProperty('java.version') as version from dual; 1.8.0_201